Alchemy/Train
This is more demanding on the graphics card.
Should not disregard the copyright permission agreed by the artist to collect data on the work for training.
Should not use the training results to devalue the original artist's work.
At the moment I personally think the results are considered the best by DreamBooth, but its training requires high VRAM (> 8GB).
How to choose
In summary, Textual Inversion and Hypernetwork apply to close to sample, with the former teaching the AI to compose a character from the labels in the model, and the latter being similar. The difference is that Hypernetwork uses the adjustment of the model weights as a means of composition, while Textual Inversion tells the AI how specific labels should be composed.
DreamBooth, on the other hand, is used for detail imitation, where the training process refurbishes the model and the new model contains new sample features (adds something new point).At the beginning, the DreamBooth technique itself is used for reproduction, so that it can recognise Rare characters&element.
As for the Aesthetic Gradients, this means that the AI is given a set of good sample. The result is something that adds detail and is easy to train, but slows down the generation of images (each generation has to be recalculated). Not really suitable for applications.
Tagger Relate
-
Multi-backend (WD taggers, deepdanbooru) fast automatic tagging utility https://github.com/AdjointOperator/Augmented-DDTagger
-
some helper script to tagging with DeepDanbooru and BLIP https://github.com/crosstyan/blip_helper
-
Labeling extension for Automatic1111's Web UI https://github.com/toriato/stable-diffusion-webui-wd14-tagger
-
Face Detection https://github.com/HRNet/HRNet-Facial-Landmark-Detection
-
Tag your waifu dataset with one enter https://github.com/AdjointOperator/End2End-Tagger
-
DeepDanbooru https://github.com/KichangKim/DeepDanbooru https://github.com/AUTOMATIC1111/TorchDeepDanbooru
-
clip+blip https://github.com/pharmapsychotic/clip-interrogator
-
FaceDetector https://github.com/hysts/anime-face-detector https://github.com/deepinsight/insightface
-
Search https://github.com/kitUIN/PicImageSearch
-
Remove text from AI-generated images https://github.com/iuliaturc/detextify
-
WatermarkDetection https://github.com/LAION-AI/LAION-5B-WatermarkDetection
-
sd-tagging-helper https://github.com/arenatemp/sd-tagging-helper
SCAL-SDT
How to train Stable Diffusion (SD) "efficiently" and how to use SCAL-SDT itself (WIP).
Cognitive model training
If you start training with the --medvram argument, you may get a RuntimeError: Expected all tensors to be on the same device error and be unable to create training.
This is a problem caused by the optimization mechanism, WebUi in this commit stable-diffusion-webui/commit/cbb857b675cf0f169b21515c29da492b513cc8c4) allows for the creation of embedding under --medvram. Please update your version beyond this one.
About batch size
Larger batch sizes may speed up training slightly and improve it slightly, but they also require larger VRAM.
About batch size
A larger batch size may speed up training slightly and improve it slightly, but it also requires a larger amount of VRAM.
Textual Inversion (TI)
A method for extracting [v] from a number of images that have a common semantic [v]. The extracted [v] tensor is called "Embedding". The Embedding is saved as a file and can then be referenced by its filename in the prompt when the image is generated.
fine tune = hn/TI/DreamArtist (APT)/DB/native training etc.
fine tune directly = DB/native training
features
Smaller training product size, webui comes with training support.
Can be used to solve problems with newly created characters that cannot be drawn, or to imitate a specific art style that can be described precisely in words. Because TI is doing the processing on the output of the Text Encoder, it does not allow the model to learn concepts it does not know.
embeddings for different models are not common
Usage
To use, put the embedding (a .pt or a .bin file) into webui's embeddings directory and write the name of the embedding to be used (without the extension) in prompt, without restarting webui.
If you use DreamArtist, put *-neg.pt together with the embeddings directory and just use them in both positive and negative prompt words.
is related
English description and effects given by webui
Related embeddings with a preview of the related effects.
list of Textual Inversion embeddings for webui(SD)
embedding library for HuggingFace
Hypernetwork (HN)
A class of network that generates weights for models, in this case for LDMs (Latent Diffusion Models). It is a more experimental approach that NAI has pioneered and explored for use on LDMs.
Features
Unlike TI, Hypernetwork modifies the weights of the LDM itself, so it can be trained in details that cannot be expressed precisely in words, and is more suitable for training in drawing styles.
The training product size is medium and webui comes with training support.
Usage
To use, put Pt into /models/hypernetworks and check Enable it in the Settings option.
There are some Hypernetworks trained by NAI in novelaileak\stableckpt\modules\modules of NAI Leaks.
Tip
.pt files, in general the small ones are embedding and the big ones are hypernetwork.
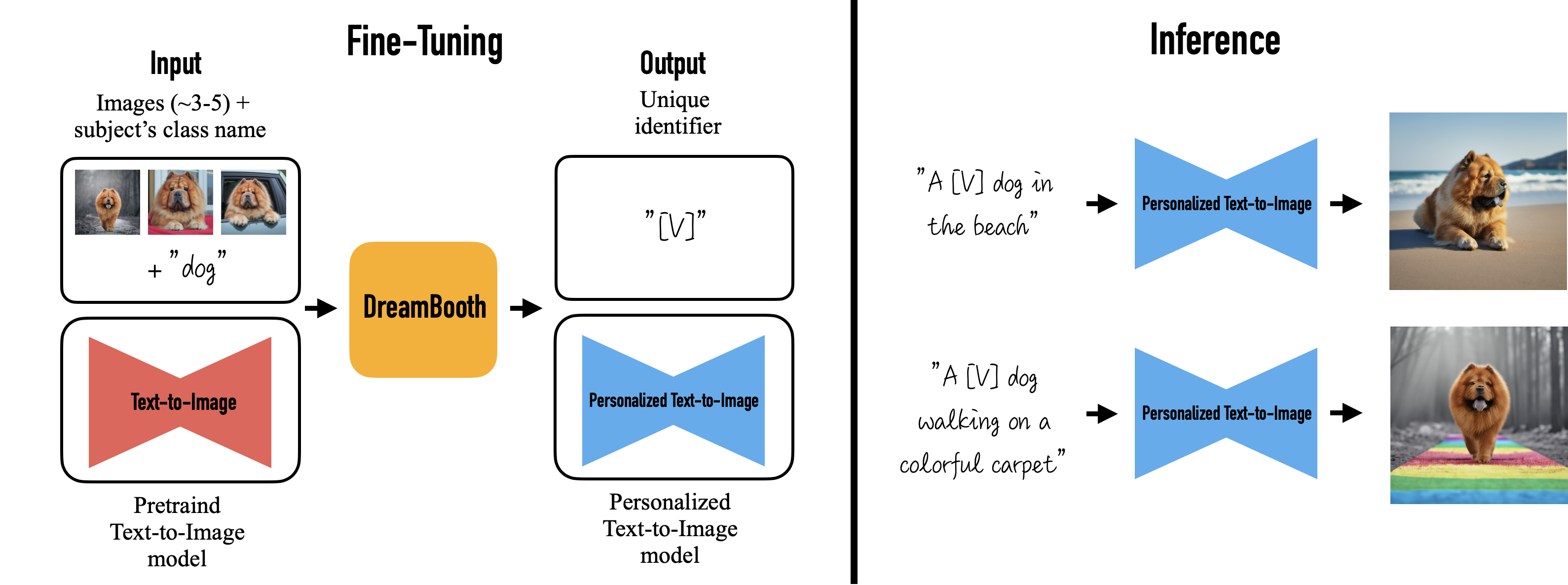
DreamBooth (DB)
A way to directly fine-tune the LDM and Text Encoder to suit the user's specific image generation needs.
Can you imagine your own dog travelling around the world, or your favourite bag on display in the most exclusive showroom in Paris? How about your parrot becoming the protagonist of an illustrated storybook?
Features
Unlike TI and HN, DreamBooth can produce images that are highly similar to the training set without losing the ability to generalise, which is particularly good for training specific figurative concepts (e.g. a character wearing a specific outfit). However, unlike TI and HN, which are plug-and-play "plug-ins" with full weights, the strength is not adjustable.
The model is not designed for learning drawing styles (abstract concepts). But it seems to be adaptable to a certain extent to the "drawing style". I leave it to the reader to experiment with the results.
Use
Put the DreamBooth trained .ckpt file into the models\Stable-diffusion directory of webui and switch to it in the top left corner of webui to use it.
Official website https://dreambooth.github.io/
Papers https://arxiv.org/abs/2208.12242
Advanced Prompt Tuning (APT)
"Can super dramatically improve the image quality and diversity"
DreamArtist-sd-webui-extension
Adds on-the-fly embedding learning of negatives to dramatically improve the quality of the resulting images. High quality concepts can be learned from individual images.
Add reconstruction loss to improve the detail quality and richness of the generated images.
Adding a discriminator trained by manual annotation (implemented using convnext) allows embedding to be learnt based on the model.
Usage same as Textual Inversion.
Aesthetic Gradients
A method for fine-tuning CLIP to suit a particular generation requirement, which can have the same effect of shortening the prompt as TI. The quality of the output may be slightly improved.
This technique provides an ``I don't say you should know where to train'' feature by calculating the weight of each image at generation time. Enables the AI to adjust and add detail more intelligently.
This feature comes from this repository and is available in this commit diffusion-webui/commit/2b91251637078e04472c91a06a8d9c4db9c1dcf0), this feature was stripped down to a plugin.
Features
With this technique, you do not need to enhance the quality of the image with too many cues, but rather maintain the original general composition of the work and improve the aesthetics. It is possible to produce good results with a small number of cues.
According to Shadow-Light 5, adding less than 25% weighting can slightly improve the aesthetics of the image without affecting the content. Aesthetics and Hypernetworks bring the Ai work closer to the original artist's style, but the aesthetic weighting itself does not work well. It needs to be combined with the Hypernetworks supernetwork.
Training this model is quick, but it is slow to produce images as it is recalculated once for each production run.
Note: When the seed changes, the training results will also change.
Usage
You can use the following Git command to install this.
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients extensions/aesthetic-gradients
Once installed, create the aesthetic-gradients` folder under the extensions` folder in webui.
To use it, put Pt in models/aesthetic_embeddings/
Then restart the application and you can use this feature in Img2Img.
